데이터 수집 단계를 처음부터 구현해 보기
2021년에는 매월 최소한 글 한 편은 블로그에 올려야겠다고 생각했습니다. 그 달에 공부했던 것, 새로 알게 된 것들을 주로 정리해서 올릴 예정입니다.
이번 달은 ‘데이터 수집 단계를 처음부터 구현해 보기’ 라는 주제로 테스트 해 본 것들을 정리해 보겠습니다.
왜 이 일을 하게 되었나?
지금 제가 회사에서 하는 일은 학생의 학습 데이터를 수집하고 분석하는 인프라를 구축/운영하는 것입니다. 3년 간 AWS를 기반으로 여러 서비스들을 운영해 보면서, ‘만약 AWS를 쓰지 않는 환경이라면, 어떻게 시스템 구축을 할 것인가?‘를 고민하게 되었습니다. 그러면서 ‘새로운 방식으로 지금까지 만들었던 것들을 다시 구축해 보면 어떨까?’ 라는 생각이 들었습니다. 그래서 데이터를 수집하고 분석하는 시스템을 처음부터 구축해 보려고 합니다.
제가 다루는 데이터는 끊임없이 데이터가 들어오는 스트리밍 데이터이므로, 이를 처리하기 위해 Kafka를 사용했습니다. 사실 AWS의 MSK와 같이 업체에 따라 Kafka를 매니지드 서비스로 제공하는 곳들이 있지만, 매니지드 서비스를 쓰지 않고 구현해 보기로 했습니다.
먼저 Kafka Broker로 들어오는 데이터는 우선 S3에 저장하도록 구성했습니다. 저는 AWS에 익숙하지만, 이번에는 시스템 구성을 위해 네이버 클라우드를 이용했습니다. 가입하고 결제 수단을 등록하면 3개월 간 10만원의 크레딧을 이용할 수 있어서 사용했습니다. 그리고 네이버 클라우드의 Object Storage는 S3와 호환이 되어서 S3 API를 쓸 수 있습니다. 그래서 지금까지 구현한 것들은 AWS의 S3 및 S3 호환 Object Storage에서 사용할 수 있을 것 같습니다. 그 외에도 Kafka의 Producer & Consumer 역할을 할 프로그램은 Python으로 구현했습니다.
지금까지 구현한 내용은 Kubernetes 클러스터에 올릴 수 있도록 구성하였습니다. 전체 구성은 GitHub 저장소를 참고해 주세요.
Kafka의 기본 구조
먼저 Kafka가 무엇인지, 어떤 경우에 사용하는지 알아보도록 하겠습니다.
Kafka의 홈페이지에 가 보면, 오픈 소스 분산 이벤트 스트리밍 플랫폼(Apache Kafka is an open-source distributed event streaming platform…)이라는 설명이 있습니다.
그러면 이벤트 스트리밍은 무엇일까요? Kakfa의 소개 페이지를 읽어보면, 이벤트 스트리밍을 다양한 소스-데이터베이스, 센서, 모바일 장비, 클라우드 서비스, 소프트웨어, …-로부터 데이터를 실시간으로 수집하는 방식으로 정의하고 있습니다. 이렇게 수집한 데이터들은 나중에 사용할 수 있도록 내구성 있게 저장되고, 실시간으로 데이터를 처리할 수도 있습니다.
Kafka는 메시지 브로커로도 사용할 수 있고, 웹 사이트 활동 추적, 시스템 모니터링, 로그 수집 등 다양한 용도로 사용할 수 있습니다. (Use Case 문서 참조) 제가 회사에서 하는 일에 대입해 보면, 활동 추적이나 로그 수집에 가까울 것 같습니다.
Kafka의 기본 구성
Kafka를 돌리려면 기본적으로 다음과 같은 구성을 필요로 합니다. Kafka와 관련된 문서를 보다 보면, 이벤트, 레코드와 같은 용어를 자주 보게 됩니다. 둘 다 같은 의미로 받아들이면 될 것 같습니다.
- ZooKeeper: 분산 애플리케이션의 고성능 조정 서비스라고 공식 문서에 설명되어 있습니다. Kafka 패키지에 들어 있는 ZooKeeper를 쓸 수도 있고, 별도의 서버로 구성해서 사용할 수도 있습니다. 단, ZooKeeper는 여러 대로 구성 시 홀수로 구성해야 합니다. (참조)
- Kafka Broker: Kafka를 실행하는 서버
- Topic: 이벤트를 분류하는 이름. Kafka 공식 문서에서는 Topic은 하나의 폴더로, 이벤트는 이 폴더에 저장되는 파일로 비유해서 설명하고 있습니다.
- Partition
- 하나의 Topic은 여러 다른 Broker에 분산되어 저장됩니다. 이렇게 해서 여러 클라이언트 애플리케이션이 여러 Broker에 동시에 데이터를 쓰고 읽을 수 있습니다.
- 이벤트가 올라가면 실제로는 Topic의 Partition들 중 하나에 쓰여지게 됩니다.
- 이 때, Partition에 올라간 이벤트는 offset을 할당받는데, 이 값은 Partition 내 각각의 이벤트를 구분하는 값입니다.
- Kafka Clients
- Producer: Kafka에 이벤트를 쓰는 클라이언트 애플리케이션
- Consumer: Kafka에 올라간 이벤트를 읽고 처리하는 클라이언트 애플리케이션
Producer와 Consumer는 완전히 분리되어 있으며, 서로를 모르는 상태로 구성되어 있습니다.
Kubernetes에 ZooKeeper, Kafka 올리기
Docker 이미지 만들기
ZooKeeper는 Docker Hub에서 공식 이미지를 제공하고 있습니다. 하지만 Kafka는 공식 이미지가 없는데요. 그래서 ZooKeeper와 Kafka를 나누어서 Docker 이미지로 구성했습니다. 이 둘을 돌리려면 Java가 필요하기 때문에, OpenJDK 11 이미지를 기반으로 ZooKeeper와 Kafka의 이미지를 만들었습니다. (Kafka와 ZooKeeper 모두 Java 8 이상을 지원합니다)
두 프로그램 모두, 상황에 따라 적절하게 설정 파일을 수정한 후 실행하도록 하였습니다.
Kubernetes에 올리기
Kubernetes에 ZooKeeper와 Kafka를 올리기 위해서 각각을 StatefulSet - Service로 구성하였습니다. StatefulSet에 있는 스토리지는 PersistentVolume으로 구성했습니다. 이유는 다음과 같습니다.
- Pod의 호스트 이름을 고정적으로 설정할 수 있음: ReplicaSet으로 구성할 때 Pod의 이름은 랜덤하게 결정되지만, StatefulSet으로 구성하면
zookeeper-0(1, 2, ...)와 같이 고정적으로 지정됩니다. - PersistentVolume을 구성함으로써, Pod이 다운되어 재시작되거나 삭제되어도 데이터를 유지할 수 있게 됩니다.
처음에는 ZooKeeper를 올리고, ZooKeeper가 정상적으로 동작하는 것을 확인한 뒤 Kafka를 올렸습니다. 그러다가 매번 순서대로 올리는 것도 귀찮아져서 아예 Helm Chart로 변경해서 한 번에 올리는 방식으로 변경했습니다.
Kafka Producer & Consumer 올리기
Producer와 Consumer 역할을 할 수 있도록 kafka-python을 이용하였습니다. 사실 여러 라이브러리가 있긴 했지만, 순수하게 파이썬으로만 구현되어 있다고 하여 kafka-python을 선택하게 되었습니다. (개인적으로는 C와 같은 언어를 사용하게 되면 CPU나 OS 측면에서 고려할 부분이 있기 때문에, 파이썬으로 만든 라이브러리는 순수하게 파이썬으로만 만든 것을 선호하는 편입니다. 물론 성능이 중요한 경우라면 상황이 달라지겠죠.)
Producer는 gunicorn + Flask 조합으로 구현했고, 앞에는 nginx Ingress를 붙였습니다. 그렇게 하여 HTTP POST로 데이터를 보내면 Kafka Topic으로 이를 보내는 기능을 구현할 수 있었습니다. 다만 Kafka 브로커로 보내는 데이터는 bytes 타입으로 만들어야 합니다.
Consumer는 Kafka Topic에서 데이터를 받다가, 10개가 차면 하나의 Object로 업로드 하도록 구성했습니다. 또한 각각의 Consumer가 동일한 데이터를 받지 않도록 하기 위해, group_id를 통일해 주었습니다.
Producer와 Consumer는 StatefulSet으로 구성할 필요가 없다고 생각하여, 그냥 Deployment - Service로 구성하였습니다.
실제로 데이터가 많이 들어오면?
실제로 데이터가 많이 들어온 경우를 가정해서 테스트 해 보았습니다. Locust를 통해서 테스트를 해 봤는데, 아래와 같은 이슈가 있네요. (Users 1,000 / Spawn Rate(Users spawned/sec) 50으로 테스트 하였습니다.)
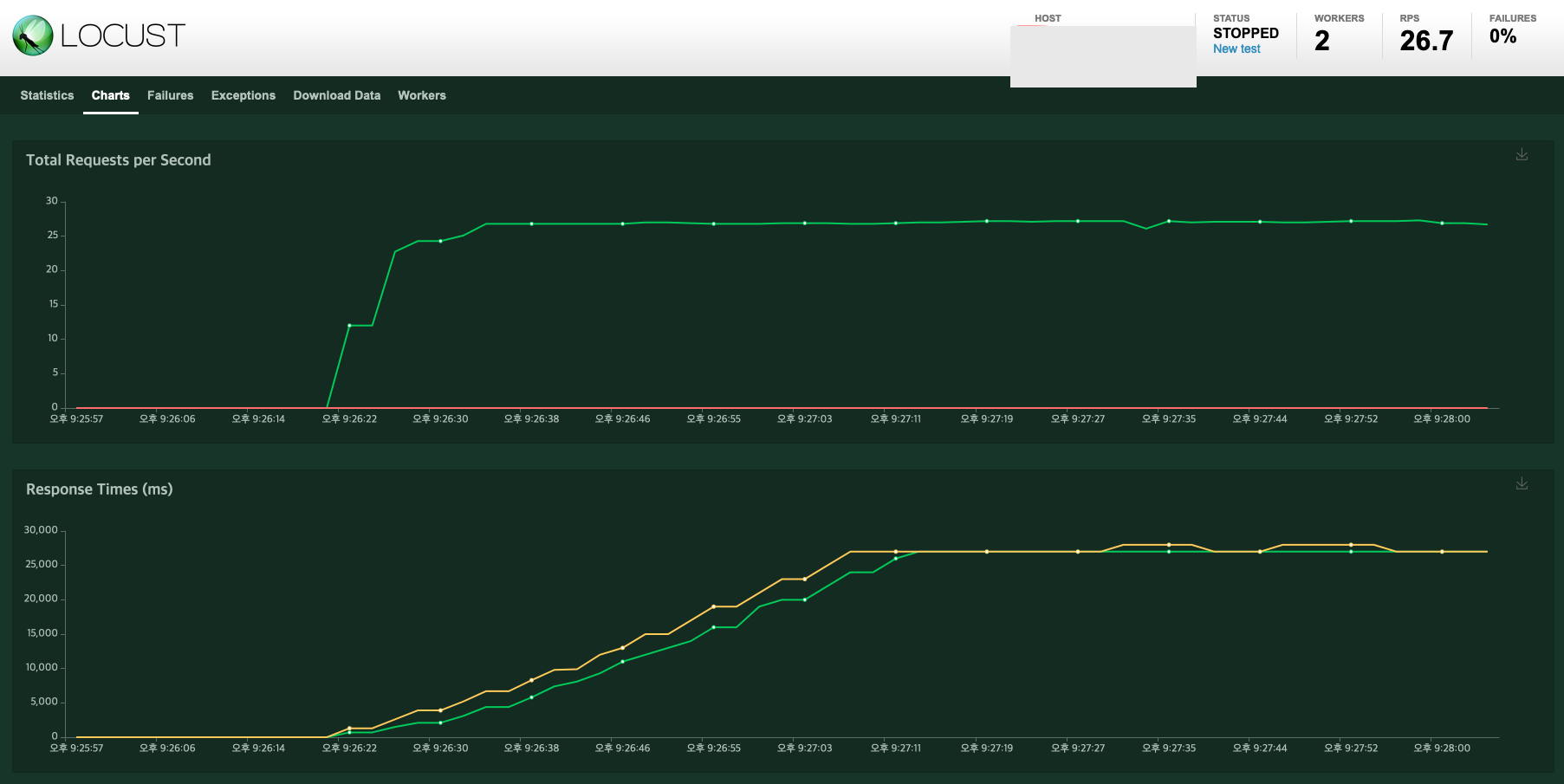
이슈 내용을 요약하면 다음과 같습니다.
- RPS 성능이 별로 좋지 않다.
- Response Time이 서서히 길어진다.
그러면 이걸 어떻게 개선해야 할까요? Response Time이 길어지는 것으로 봐서는 Kafka에서 Request 처리를 제대로 못 하는 것 같습니다.
Partition 수를 확인해 볼까요?
kubectl exec -it kafka-0 -- bash
# 여기부터는 컨테이너 내부에서 실행한 내용입니다.
root@kafka-0:/kafka# cd kafka_2.13-2.6.0/bin
root@kafka-0:/kafka# ./kafka-topics.sh --describe --bootstrap-server localhost:9092 --topic test-topic
Topic: test-topic PartitionCount: 1 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: test-topic Partition: 0 Leader: 1 Replicas: 1 Isr: 1
그러면 Kafka Topic의 Partition 수를 좀 더 늘려 보았습니다.
root@kafka-0:/kafka/kafka_2.13-2.6.0/bin# ./kafka-topics.sh --bootstrap-server localhost:9092 --alter --topic test-topic --partitions 6
root@kafka-0:/kafka/kafka_2.13-2.6.0/bin# ./kafka-topics.sh --describe --bootstrap-server localhost:9092 --topic test-topic
Topic: test-topic PartitionCount: 6 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: test-topic Partition: 0 Leader: 1 Replicas: 1 Isr: 1
Topic: test-topic Partition: 1 Leader: 2 Replicas: 2 Isr: 2
Topic: test-topic Partition: 2 Leader: 0 Replicas: 0 Isr: 0
Topic: test-topic Partition: 3 Leader: 1 Replicas: 1 Isr: 1
Topic: test-topic Partition: 4 Leader: 2 Replicas: 2 Isr: 2
Topic: test-topic Partition: 5 Leader: 0 Replicas: 0 Isr: 0
파티션을 6개, 30개까지 늘려 봐도 결과는 똑같았습니다. 혹시 몰라 Nginx Ingress 컨트롤러 쪽 로그를 확인해 보니, 다음과 같은 로그가 있었습니다.
198.18.0.1 - - [27/Jan/2021:14:04:35 +0000] "POST /upload HTTP/1.1" 499 0 "-" "python-requests/2.25.1" 227 16.391 [default-kafka-producer-service-80] [] 198.18.1.103:5000 0 16.389 - 0ce472a8362f96fd9500d1dc310428cd
중간을 보시면 16.391이라는 숫자가 있고, 좀 더 오른쪽으로 이동하면 16.389라는 숫자가 있습니다.
이 숫자들이 의미하는 것을 ingress-nginx의 문서에서 찾아보니, 다음과 같이 설명하고 있네요.
- 왼쪽 숫자는
$request_time으로, 클라이언트로부터 첫번째 바이트를 읽은 시간부터 소요된 시간을 의미합니다. - 오른쪽 숫자는
$upstream_request_time으로, upstream server로부터 응답을 받는 데 걸리는 시간을 초 단위로 milliseconds까지 표현한다고 합니다.
그러면 결론은, Upstream 서버에서 요청~응답을 받는 시간이 너무 오래 걸린다는 의미입니다. 그리고 Upstream 서버라면 제가 만든 Producer 프로그램을 의미할 것입니다. Producer에 문제가 있는지 고민해 보겠습니다.
생각해 보니, 이 문제는 Producer 쪽으로 요청이 들어올 때마다 계속해서 연결을 시도하여 발생했습니다. 그래서, 처음 Producer 애플리케이션이 시작할 때 Kafka에 연결하고, 요청을 처리할 때 이 연결을 참조하도록 프로그램을 수정하였습니다. 어떻게 보면 기본적인 부분인데 좀 부끄럽네요 😅
그렇게 해서 동일 조건으로 테스트 해 보니, 성능이 확실히 향상된 것을 볼 수 있었습니다.
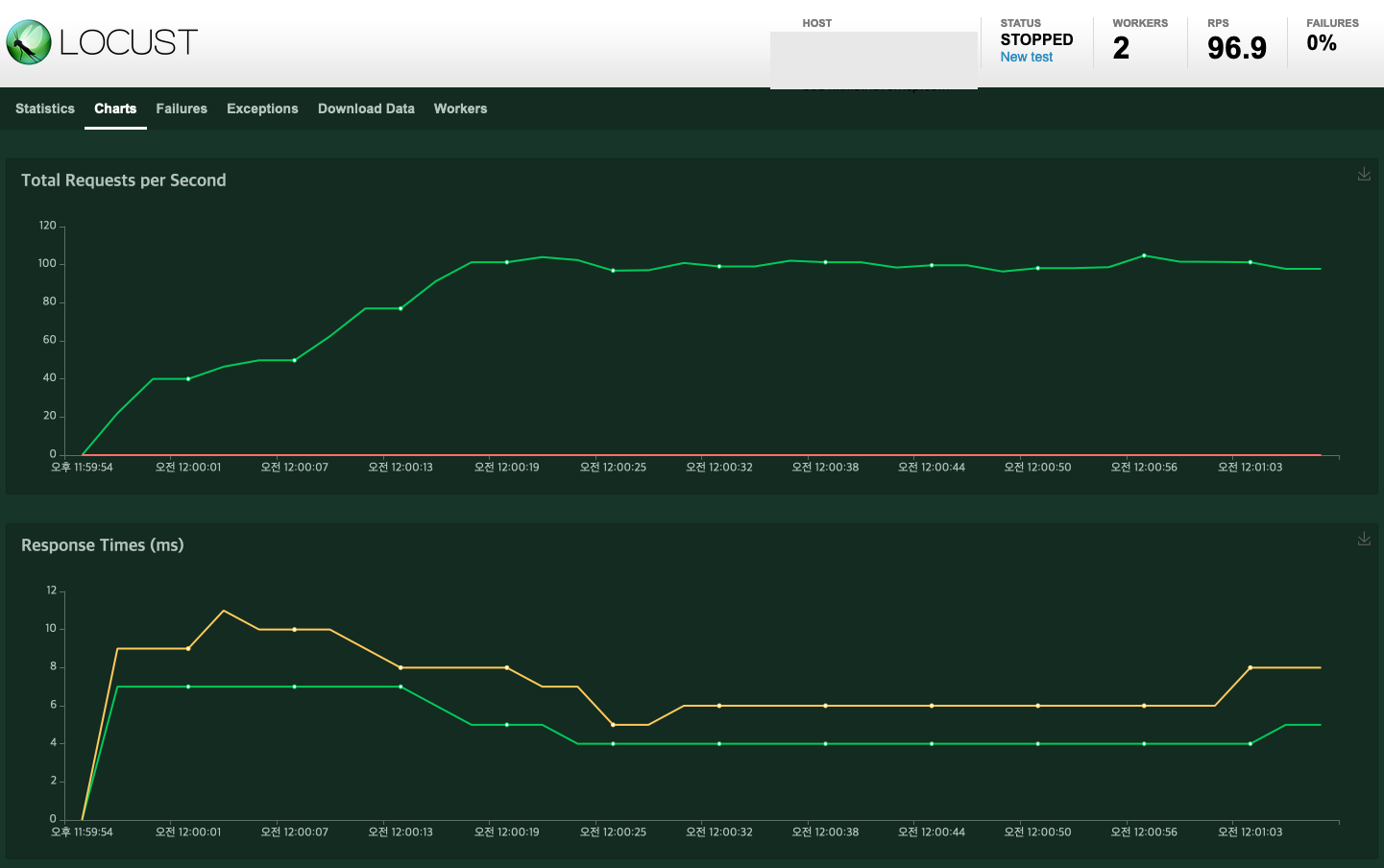
앞에서 언급했던 Partition의 개념을 생각해 보면, Partition 개수 조정과 함께 다음 내용도 고려해야 할 것 같습니다.
- 여러 클라이언트가 같은 Topic의 서로 다른 Partition에 데이터를 올리거나 처리할 수 있게 구성한다.
- Replication Factor를 조정해서 데이터를 여러 Broker에 복제하여 저장할 수 있도록 한다. (Fault tolerant & High Availability 목적, topic-partition 단위로 replication이 수행됨)
좀 더 개선할 것들은 없을까?
데이터 수집 환경을 구성하면서, 가장 부족하다고 생각했던 것은 모니터링 환경이 없다는 것이었습니다. 장기적으로는 Pod들의 로그를 수집하고 한 곳에서 볼 수 있는 환경을 만들어 볼 생각입니다.
또한 Docker 이미지를 새로 빌드했을 때, 이미지의 버전 관리를 어떻게 할 것인지도 이슈일 것 같습니다.
이러한 문제들은 조금씩 준비해서 해결해 보려고 합니다.
(3월 1일 추가) Fluentd와 Elasticsearch로 모니터링 환경 구성하기
추가로 2월 초에는 컨테이너 모니터링을 위해 Fluentd와 Elasticsearch로 모니터링 환경을 구성하였습니다. 어떻게 구성했는지, 그리고 구성 과정에서 겪은 것들에 대해 이야기해 보겠습니다.
Fluentd + Elasticsearch 구성
컨테이너 로그 수집을 위해 Fluentd를 이용하였습니다. 그리고 Fluentd에서 수집한 로그는 Elasticsearch로 보내도록 설정했습니다.
Fluentd를 k8s 클러스터에 설정할 때 DaemonSet을 이용했는데요. 클러스터 내 노드 수만큼 Fluentd를 올려서 클러스터 전체를 모니터링 할 수 있기 때문입니다.
제가 참고한 문서는 다음과 같습니다.
Fluentd는 Elasticsearch 외에도 여러 곳으로 로그를 보낼 수 있는데요. 저는 Elasticsearch를 선택했습니다. 만약 실제 서비스로 이것을 구축했을 때, 서비스 상태에 영향을 받지 않도록 하기 위해 Elasticsearch는 Kubernetes 클러스터 외부에 구축했습니다.
이 시점에도 네이버 클라우드의 크레딧이 남아서 네이버 클라우드의 Elasticsearch Service를 이용했는데요.
AWS의 Elasticsearch Service와 비교하면, Public Subnet에 클러스터를 구성해도 Public Endpoint가 생성되지 않기 때문에 외부 네트워크에서 접속할 수 있는 환경을 수동으로 구성해 주어야 합니다. 저는 네이버 클라우드의 문서를 참고해서, 클러스터 앞에 Load Balancer를 구성했습니다.
한편, Fluentd로 로그를 수집할 때, 다음과 같은 에러 메시지가 계속 찍히는 경우가 있습니다.
Systemd::JournalError: No such file or directory retrying in 1s
참고로 systemd는 리눅스에서 시스템과 서비스를 관리하는 프로그램인데요. 보통 systemd는 PID가 1인데, 컨테이너 안에서는 최초에 실행하는 프로세스가 PID 1번을 받는 경우가 있나 봅니다. 제 생각에는 이 때문에 위의 로그가 찍히는 것 같은데요. 이 경우 FLUENTD_SYSTEMD_CONF 환경 변수를 disabled로 설정하면 로그가 찍히지 않습니다.
RBAC 설정
Fluentd가 Pod 로그를 가져와서 실행하려면, DaemonSet으로 실행하는 Fluentd는 클러스터 내부의 Pod 정보를 가져올 수 있는 권한이 있어야 합니다. 그렇기 때문에 RBAC(Role-Based Access Control)을 이용했는데요. 다음과 같이 구성하였습니다.
- Fluentd가 사용할 ServiceAccount를 생성합니다.
- Cluster에 적용할 ClusterRole을 생성합니다.
- ServiceAccount - ClusterRole을 연결하는 ClusterRoleBinding을 생성합니다.
- DaemonSet Spec에 serviceAccount를 연결합니다.
전체적인 내용은 GitHub에 작성한 Template을 참고하세요.