데이터 분석 워크플로우를 처음부터 만들어 보기
지난 달에는 데이터 수집을 위한 환경 구성을 처음부터 만들어 보았습니다. 어느 정도 초기 환경을 구축했다고 판단해서, 이번에는 데이터 분석을 위한 워크플로우를 처음부터 만들어 보는 과정을 기록해 보려고 합니다.
이번에는 Apache Airflow를 이용해서 데이터 분석 작업을 위한 환경을 구축해 보았습니다. 여러 곳에서 Airflow를 사용하는 사례를 듣다 보니, Airflow를 한번 써 봐야겠다고 생각했습니다. 최근에는 AWS에서도 Managed Workflows for Apache Airflow라는 관리형 서비스를 제공하고 있고, GCP에서는 Cloud Composer라는 이름으로 관리형 서비스를 제공하고 있습니다.
사실 전체 아키텍처 구성과 DAG 테스트를 해보고 싶었는데요. 2월이 짧다보니, 우선 기본적인 아키텍처를 이해하기 위해 노력하였습니다.
전체 내용은 GitHub 저장소에서 확인하실 수 있습니다.
Airflow의 기본적인 아키텍처
Airflow의 아키텍처는 Basic Airflow Architecture 문서를 참고하시면 확인할 수 있습니다.
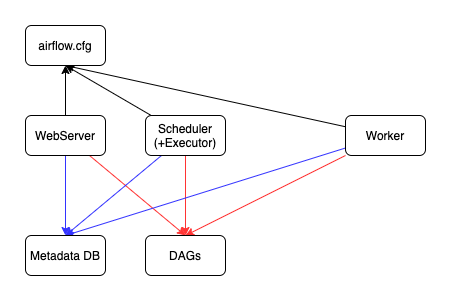
링크한 문서나 위의 그림을 보면서 기본적으로 필요한 것들을 정리하면 다음과 같습니다.
- 메타데이터 DB: 데이터 파이프라인에 대한 메타데이터를 저장합니다. 기본값으로는 SQLite를 이용하고, PostgreSQL, MySQL 등을 사용할 수 있습니다.
- DAGs: DAG(Directed Acyclic Graph)은 실행하고자 하는 태스크와 그 관계를 정의한 파일입니다. 이를 어딘가에 저장할 장소가 필요합니다.
- Web Server: 메타데이터 DB, DAG 저장소와 연동하여 전체적인 파이프라인을 웹에서 관리할 수 있습니다.
- Scheduler: 웹 서버와는 별도의 프로세스로 작업을 스케줄링 하는 역할을 합니다. 마찬가지로 메타데이터 DB, DAG 저장소와 연동합니다.
- Worker: 실제로 Task를 수행하는 주체입니다.
그리고 Airflow의 설정 파일인 airflow.cfg 파일이 필요합니다. Web Server, Scheduler, Worker 모두 동일한 설정 파일을 사용할 수 있도록 해야겠네요.
이렇게 하여 다음과 같이 구성하게 되었습니다.
- 메타데이터 DB를 클러스터 외부에 구성
- DAG 저장소는 서로 공유할 수 있도록 구성
airflow.cfg파일은 Docker 이미지에 추가- 동일한 Docker 이미지로 Web Server와 Scheduler를 따로 실행
로그가 왜 안 보이지?
전체적인 구성을 로컬에서 테스트 하다가, 웹 서버에서 Task 로그를 확인할 수 없는 문제를 확인했습니다. Airflow의 Logging and Monitoring Architecture 문서에 답이 있었는데요.
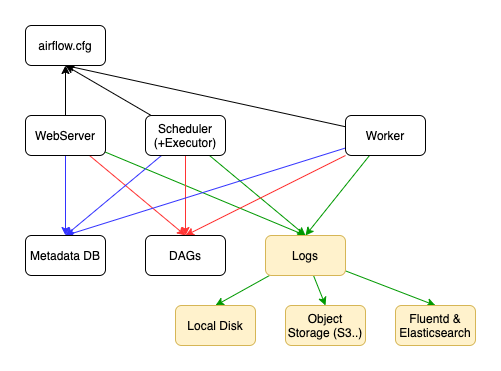
링크한 페이지의 그림이나 위의 그림을 보시면, Web Server, Scheduler, Worker(가 실행하는 Task)에서 로그가 발생함을 알 수 있습니다. 로그를 한 곳에 모으고, 이를 Web Server에서 조회할 수 있어야 Web Server에서 Task 로그를 확인할 수 있습니다.
이를 위해 다음과 같은 방법을 고려할 수 있을 것 같습니다.
- 로그를 PersistentVolume에 저장
- S3와 같은 Object Storage에 로그를 저장
- Fluentd & ElasticSearch에 저장
Kubernetes 클러스터 내 노드가 하나인 경우는 일반적인 블록 스토리지 기준으로 PersistentVolume을 사용하면 되는데요. 문제는 여러 노드에 분산이 되는 경우입니다. 이 경우에는 ReadWriteMany 모드를 사용할 수 있는 스토리지로 PersistentVolume을 구성해야 합니다. (참고) 그래서 NFS를 이용해서 스토리지를 만들고, 이를 로그 저장용으로 사용하였습니다.
구성은 다음 링크를 참고해 주세요.
Executor, 무엇을 선택할까?
처음에 Quick Start 정도만 읽었다면 간과하기 쉬운 것이 Executor일 것입니다. Airflow의 Executor는 스케줄러와 함께 동작하는 프로세스로, Task 인스턴스를 어떻게 실행할 것인지를 결정하는 방식이라고 보면 될 것 같습니다. Airflow와 관련된 문서에서 자주 볼 수 있는 Executor는 다음과 같습니다.
- SequentialExecutor: 기본값으로,
sqlite를 사용하는 경우 쓸 수 있는 유일한 Executor입니다. 말 그대로 Task를 순서대로 하나씩 실행하는 Executor입니다. Production 환경에서는 권장하지 않습니다. - LocalExecutor: 프로세스를 생성함으로써 Task를 실행합니다. 생성하는 프로세스의 수를 조절하기 위해
parallelism설정을 이용할 수 있습니다. - CeleryExecutor: Worker를 스케일 아웃 할 수 있는 방법 중 하나입니다. Celery를 사용하기 위해서는 메시지 브로커가 필요하므로, Redis나 RabbitMQ를 함께 구성해야 합니다.
- KubernetesExecutor: 1.10.0 버전부터 이용할 수 있습니다. Kubernetes Executor는 모든 Task Instance에 대해 새로운 Pod을 만듭니다.
저는 Kubernetes 클러스터에 올려서 테스트를 했기 때문에, 자연스럽게 KubernetesExecutor를 이용하게 되었습니다.
먼저 KubernetesExecutor를 이용하려면, airflow.cfg 파일에 설정하거나 AIRFLOW__CORE__EXECUTOR 환경변수에 KubernetesExecutor를 지정하면 됩니다.
그리고 다음 내용을 고려해야 합니다. (CeleryExecutor를 사용하는 경우도 동일)
- Web Server, Scheduler, Worker 모두 동일한 메타데이터 DB에 접근할 수 있어야 합니다.
- Web Server, Scheduler, Worker 모두 동일한 DAG 저장소에 접근할 수 있어야 합니다. (그래서 DAG 저장소도 NFS로 구성하여, 클러스터 내 노드가 달라도 접근이 가능하도록 했습니다. 아니면 Git으로 동기화 하는 방법도 있다고 하네요)
- Worker 역할을 하는 서버나 컨테이너도 Airflow가 설치되어 있어야 합니다.
또 추가로 다음과 같은 내용을 고려해야 합니다.
- 로그를 Persistent Disk에 저장해야 합니다. 기본적으로 Task가 끝나면 Pod이 자동으로 삭제되기 때문입니다.
- 로그를 디스크 대신 S3와 같은 스토리지에 저장하는 방법도 있습니다.
이번에 테스트를 하면서 노드 1개에 Persistent Volume을 할당해서 로그를 저장하도록 했습니다. 그런데 DAG 실행을 테스트 했을 때 Task 로그가 저장되지 않는 문제가 있었습니다. 그래서 좀 더 테스트를 해 보거나 S3와 같은 스토리지에 저장하는 방법을 고려해야 할 것 같네요.
분석에 필요한 것들을 함께 설치하기
Airflow를 설치하면, 기본적으로 Airflow를 실행하기 위한 기능만 설치합니다. 만약 DB에 접근해야 한다거나, S3와 같은 스토리지에 데이터를 저장한다거나, Kubernetes를 이용하려면 추가 패키지를 설치해야 하는데요.
예를 들어 MySQL을 사용해야 하는 경우 두 가지 방법이 있습니다.
- Extras:
pip install 'apache-airflow[mysql]'과 같은 방법으로 설치 - Providers: Airflow 2.0 버전부터 지원.
pip install 'apache-airflow-providers-mysql'명령으로 설치 가능
대부분의 extras는 provider를 dependency로 추가해서, extras를 설치하면 provider 패키지가 함께 설치됩니다. 다만 extras 중에는 provider를 설치하지 않는 경우도 있다고 하네요.
그리고 MySQL extra를 설치하는 경우, DB와 관계된 라이브러리를 OS에 미리 설치해야 하는 경우가 있습니다.
- 예: MySQL + Ubuntu(Debian)인 경우,
libmysqlclient-dev또는default-libmysqlclient-dev를 OS에 설치
더 해볼 것들
기본적인 DAG의 구조는 Airflow Tutorial 문서에서 확인할 수 있습니다. Task, Jinja Template, Dependencies, 문서화 설정 등에 대해 간단히 배워볼 수 있는데요.
이를 바탕으로 DAG을 어떻게 구성해야 할 지를 테스트 해 보려고 합니다. 예를 들면 다음과 같은 경우가 있는데요.
- DW, DB 등에서 데이터 쿼리 후 분석 작업 수행
- S3에서 데이터 쿼리 후 분석 작업 수행
- 이전 Task의 결과를 다음 Task에서 사용할 수 있는 방법
- 실패 시 재작업이 필요한 경우 어떻게 하면 좋을지?
이 부분은 3~4월 중으로 조금씩 공부해 볼 예정입니다.