Argo Workflows 이용해 보기
예전에 여러 단계가 있는 작업을 해야 할 때 AWS의 Step Functions를 이용한 적이 있었습니다. Step Functions의 경우, Lambda 함수를 연결해서 쓴 적이 많았고, 오래 걸리는 작업은 다른 방법으로 구축할 수 있습니다. (이전에 올렸던 Python으로 Step Functions 활동 만들기 문서를 참고해 주세요)
한편, 다른 방법은 없나 찾아보다가 Airflow를 알게 되었습니다. 그래서 Airflow도 테스트한 적이 있었는데요. (이전에 올렸던 데이터 분석 워크플로우를 처음부터 만들어 보기 1편, 2편을 참고해 주세요)
최근 우연하게 Kubernetes에서 Workflow를 관리할 수 있는 Argo Workflow에 대해 알게 되었습니다. 그래서 이번 글에서는 Argo Workflow의 사용법을 알아보고자 합니다.
저는 로컬 환경에서 Rancher Desktop을 이용해서 테스트하였습니다. (즉, 로컬 환경에서 Kubernetes를 구동시킬 수 있는 상황이면 아래 내용을 테스트 할 수 있습니다)
설치 방법
이 글을 작성하는 시점의 최신 버전인 3.5.8 버전을 이용해 보겠습니다. 터미널에서 아래 명령을 입력해 주세요.
ARGO_WORKFLOWS_VERSION="v3.5.8"
kubectl create namespace argo
kubectl apply -n argo -f "https://github.com/argoproj/argo-workflows/releases/download/${ARGO_WORKFLOWS_VERSION}/quick-start-minimal.yaml"
위의 명령은 테스트용 설치 과정입니다. 프로덕션 목적으로 Argo Workflows를 구축하려면 문서를 참조해 주세요.
UI에서 확인하기
Argo Workflows는 웹에서 확인할 수 있는 환경을 제공합니다. 포트 포워딩을 하기 위해 터미널에서 아래 명령을 입력해 주세요.
kubectl -n argo port-forward svc/argo-server 2746:2746
웹 브라우저에서 https://localhost:2746 으로 접속하면 아래와 같은 화면을 볼 수 있습니다.
Service Account 및 RBAC 설정
Argo가 Kubernetes API를 이용해서 Kubernetes 리소스와 통신하기 위해, ServiceAccount, Role, RoleBinding 설정이 필요합니다.
ServiceAccount를 지정하지 않으면, namespace 내 default ServiceAccount를 이용한다고 하는데요. 이 경우 권한이 충분하지 않아 에러가 발생할 수 있습니다. (참고자료)
최소한으로 필요한 권한을 이용해서 다음과 같이 ServiceAccount와 권한을 설정해 보겠습니다.
apiVersion: v1
kind: ServiceAccount
metadata:
name: argo-workflow-sa
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: executor
rules:
- apiGroups:
- argoproj.io
resources:
- workflowtaskresults
verbs:
- create
- patch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: executor-binding
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: executor
subjects:
- kind: ServiceAccount
name: argo-workflow-sa
위 파일을 rbac.yaml 파일로 저장 후, 터미널에서 kubectl apply -f rbac.yaml 명령을 실행하면 됩니다.
사용 사례
공식 문서에서는 작업을 실행할 때 Argo CLI를 이용하는 것을 권장하는데요. 하지만 kubectl을 이용해서 실행할 수도 있습니다. 이 문서에서는 kubectl을 이용해서 리소스를 생성하고 테스트 해 보겠습니다.
예전에 Step Functions를 사용했던 경험으로, 유사한 기능을 지원하는지 확인해 보려고 합니다.
Case 1: 기본 동작
기본 동작을 확인하기 위해 Walk through 문서의 hello world 예제로 시작합니다. 다만 수정할 부분이 하나 있는데요. 앞에서 만든 ServiceAccount를 지정해 줍니다. 이후에 나오는 예제에도 동일하게 설정해야 정상적으로 동작합니다. (serviceAccountName 속성)
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: hello-world-
spec:
entrypoint: whalesay
serviceAccountName: argo-workflow-sa # 이 줄을 추가해 주세요!
templates:
- name: whalesay
container:
image: docker/whalesay
command: [ cowsay ]
args: [ "hello world" ]
resources:
limits:
memory: 32Mi
cpu: 100m
hello-world-workflow.yaml 파일로 저장 후, 터미널에서 kubectl create -f hello-world-workflow.yaml을 입력하여 실행합니다.
참고:
metadata.generateName속성이 있기 때문에kubectl create명령으로 생성해야 합니다. (출처)
Argo UI로 이동해서, 왼쪽 Argo 로고 바로 밑의 Workflows 메뉴를 클릭합니다. 목록에서 방금 실행된 작업 이름을 클릭하면, 아래와 같은 화면을 볼 수 있습니다. 체크 표시를 클릭하면 수행한 작업에 대한 정보를 볼 수 있습니다.
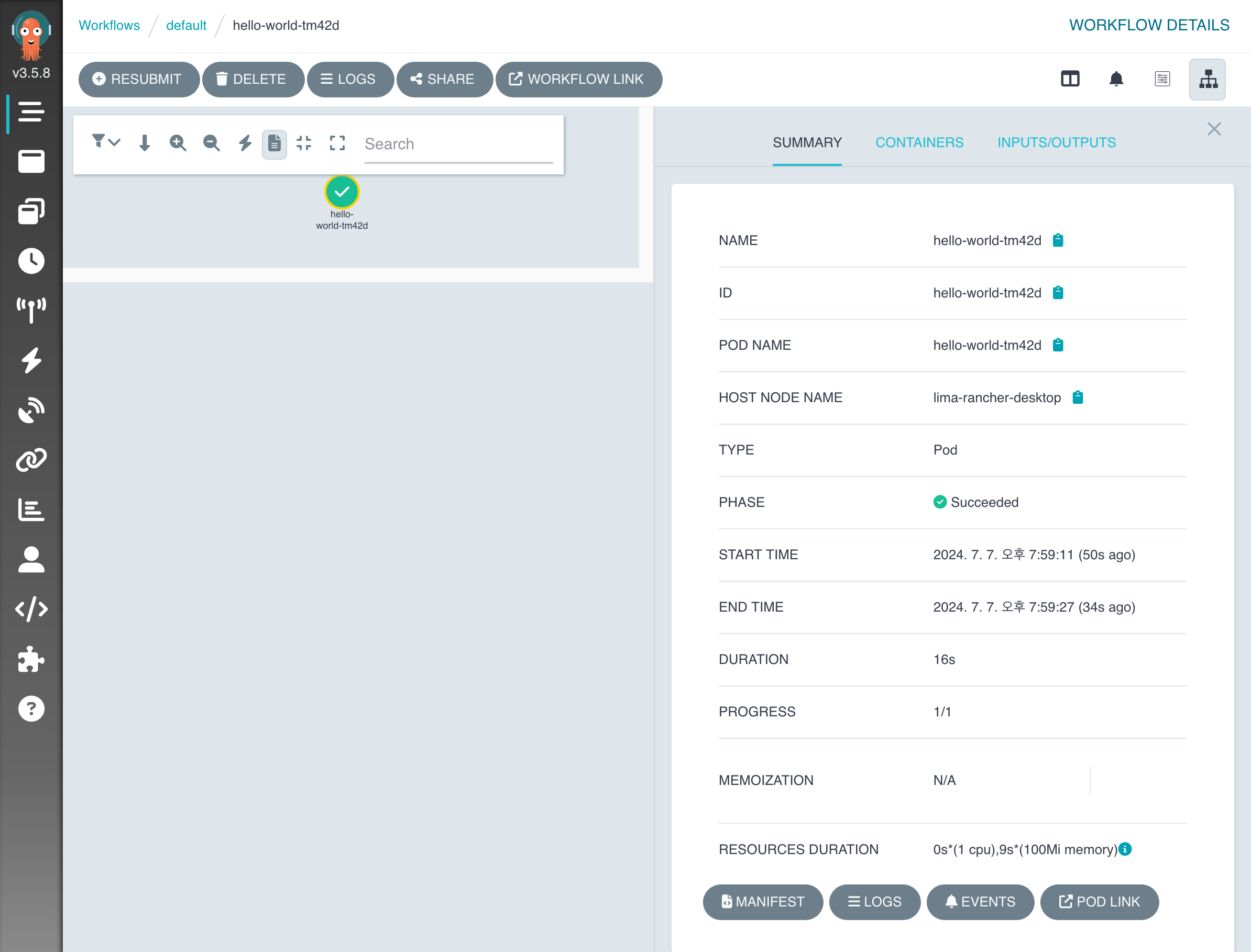
하단의 Logs를 클릭하면 실행된 작업의 출력을 확인할 수 있습니다.
Case 2: 여러 Step을 수행
Walk through 문서의 Steps 예제로 테스트 해 봅니다.
다만 성공적인 실행을 위해 spec.serviceAccountName 속성을 지정해서 실행합니다.
실행 결과를 한 번 살펴볼까요?
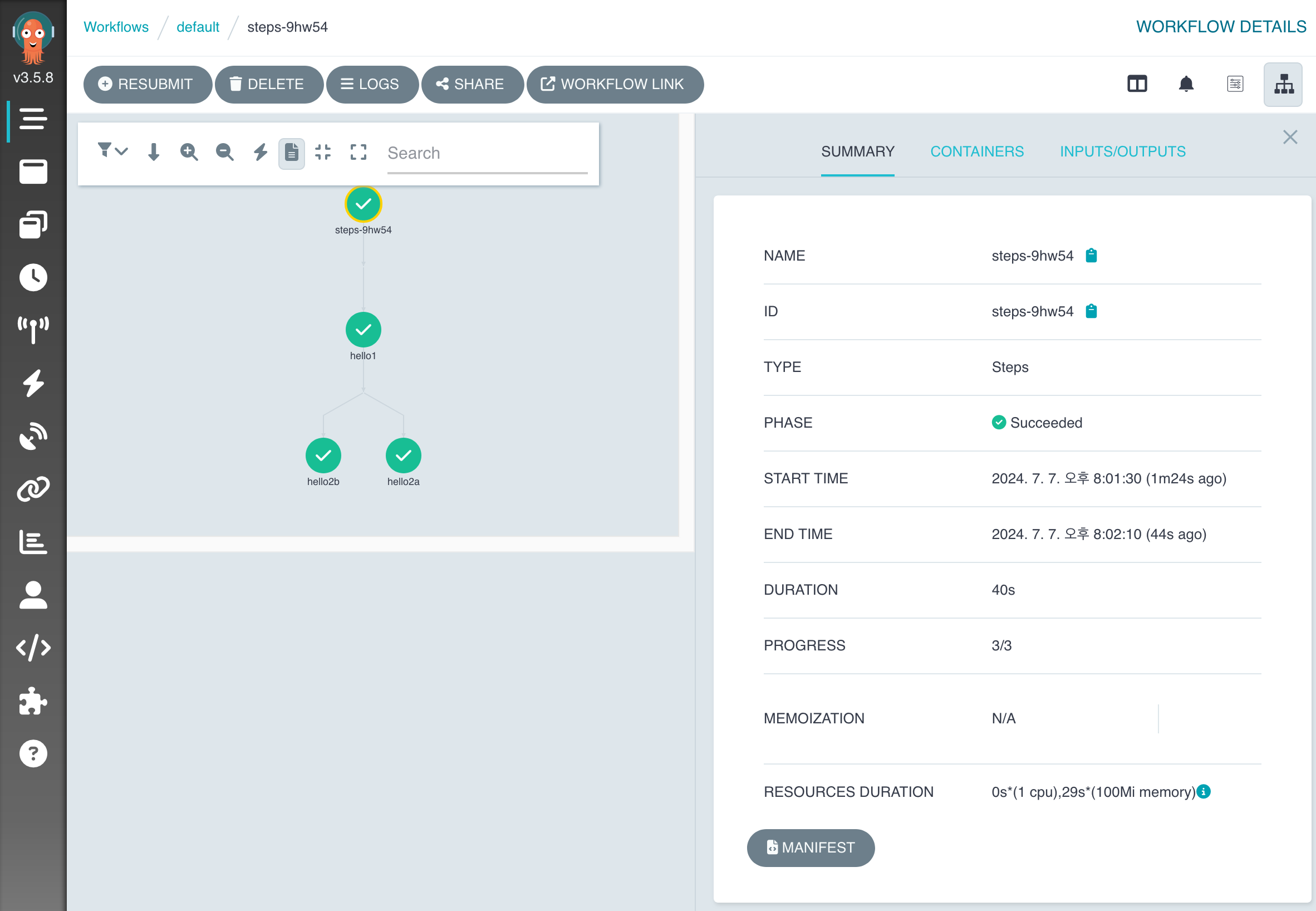
(사용한 YAML 파일은 Steps 예제 문서를 참고해 주세요)
spec.entrypoint: hello-hello-hello설정에 따라hello-hello-helloTemplate의 내용을 수행합니다.- 각각의 작업은
steps에 지정한 순서로 실행됩니다. - 각각의 작업은
whalesaytemplate에 있는 작업을 수행합니다.
- 각각의 작업은
- 작업에서 Parameter를 지정할 때에는
arguments.parameters부분에 필요한 것들을 지정해 줍니다. hello1을 실행한 후에는hello2a,hello2b가 병렬적으로 실행되는 것을 볼 수 있습니다.
Case 3: DAG
Airflow에 익숙하시다면 DAG(Directed Acyclic Graph)에 대해 들어본 적이 있으실 것입니다. DAG는 방향이 있지만 순환하지 않는 그래프입니다. Airflow와 마찬가지로 Argo Workflows에서도 DAG를 지원합니다. Case 2의 Steps와 다르게, 각각의 작업에 의존성을 지정할 수 있는데요. dependencies 속성으로 지정할 수 있습니다.
Walk through 문서의 DAG 문서로 테스트 해 보겠습니다. 이번에도 잊지 마시고 spec.serviceAccountName에 ServiceAccount를 지정해 주세요.
예제의 내용 중 spec 부분을 보시죠.
spec:
entrypoint: diamond
serviceAccountName: argo-workflow-sa # 실행할 때 추가해 주세요.
templates:
# DAG의 각 단계가 수행할 작업입니다. 단순히 echo로 메시지를 출력합니다.
- name: echo
inputs:
parameters:
- name: message
container:
image: alpine:3.7
command: [echo, "{{inputs.parameters.message}}"]
# DAG를 설정합니다.
- name: diamond
dag:
tasks:
- name: A
template: echo
arguments:
parameters: [{name: message, value: A}]
- name: B
dependencies: [A] # B는 A에 의존성이 있습니다.
template: echo
arguments:
parameters: [{name: message, value: B}]
- name: C
dependencies: [A] # C도 A에 의존성이 있습니다.
template: echo
arguments:
parameters: [{name: message, value: C}]
- name: D
dependencies: [B, C] # D는 B, C에 의존성이 있습니다.
template: echo
arguments:
parameters: [{name: message, value: D}]
실제로 수행해 보면 다음과 같습니다.
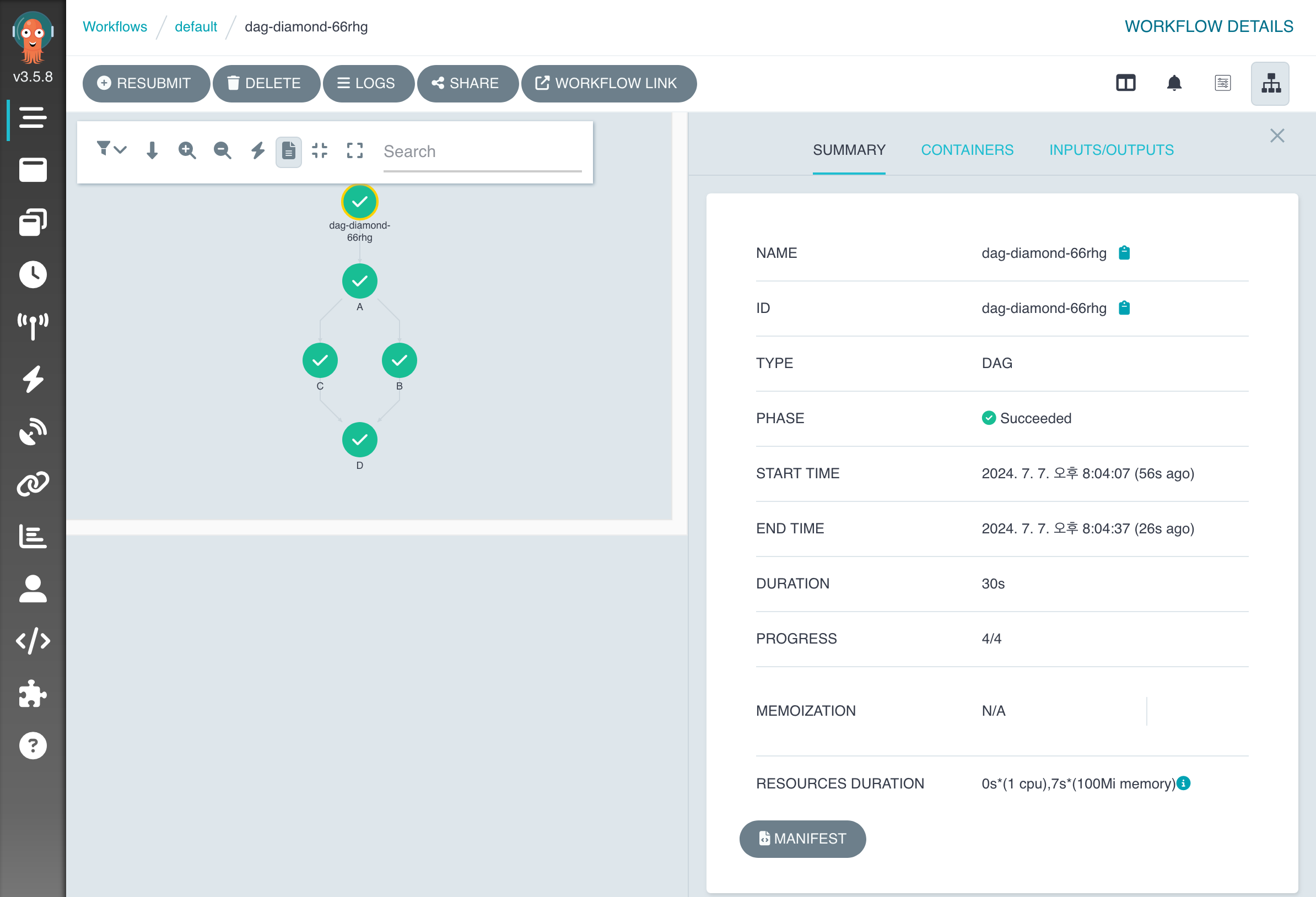
- A가 완료되면, B와 C를 동시에 실행합니다.
- B와 C가 모두 끝나면 D를 실행합니다.
Case 4: 이전 작업의 결과값을 다음 작업의 입력값으로 사용
이전 작업의 결과값을 다음 작업의 입력값으로 사용해야 할 때가 있습니다. 이럴 때는 어떻게 하는지 살펴보도록 하겠습니다.
Walk through 문서의 Output Parameters 예제를 가지고 테스트 해 보겠습니다. 이번에도 spec.serviceAccountName 항목을 설정해 주세요.
이 예제는 generate-parameter → consume-parameter 순으로 실행합니다. 아래 YAML에서 steps 부분을 참고해 주세요.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: output-parameter-
spec:
entrypoint: output-parameter
templates:
- name: output-parameter
steps:
- - name: generate-parameter
template: whalesay
- - name: consume-parameter
template: print-message
arguments:
parameters:
- name: message
value: "{{steps.generate-parameter.outputs.parameters.hello-param}}"
generate-parameter 단계의 결과는 /tmp/hello_world.txt 파일에 저장되고, 이를 outputs.parameters 항목에 hello-param이라는 이름으로 등록합니다. (아래 YAML 참조)
- name: whalesay
container:
image: docker/whalesay:latest
command: [sh, -c]
args: ["echo -n hello world > /tmp/hello_world.txt"] # hello_world.txt 파일 생성
outputs:
parameters:
- name: hello-param # output parameter의 이름
valueFrom:
path: /tmp/hello_world.txt # hello-world.txt의 내용으로 hello-param 값을 지정
두번째 단계인 consume-parameter 작업에서는 arguments.parameters 단계에 이전 단계에서 지정된 hello-param 값을 가져오도록 합니다.
spec:
entrypoint: output-parameter
templates:
- name: output-parameter
steps:
# 중간 생략
- - name: consume-parameter
template: print-message
arguments:
parameters:
# generate-parameter 단계의 hello-param output을 print-message의 input으로 전달
- name: message
value: "{{steps.generate-parameter.outputs.parameters.hello-param}}"
# 중간 생략
# consume-parameter가 실제로 수행하는 작업입니다.
- name: print-message
inputs:
parameters:
- name: message
container:
image: docker/whalesay:latest
command: [cowsay]
args: ["{{inputs.parameters.message}}"]
최종 실행 결과는 다음과 같이 hello world라는 메시지입니다.
_____________
< hello world >
-------------
\
\
\
## .
## ## ## ==
## ## ## ## ===
/""""""""""""""""___/ ===
~~~ {~~ ~~~~ ~~~ ~~~~ ~~ ~ / ===- ~~~
\______ o __/
\ \ __/
\____\______/
time="2024-07-06T13:32:58 UTC" level=info msg="sub-process exited" argo=true error="<nil>"
DAG를 이용하는 경우, steps 대신에 tasks라는 이름으로 다른 작업(task)의 output 값을 참조할 수 있습니다. (예: {{tasks.generate-parameter.outputs.parameters.hello-param}})
마무리
이렇게 Argo Workflow의 기본적인 사용 방법을 알아봤습니다. Kubernetes 기반으로 Workflow를 구성할 때, Airflow의 KubernetesExecutor를 이용할 수도 있을 텐데요. 주변 동료들이 Kubernetes manifest 작성에 익숙하지만, Python에 익숙하지 않다면 Argo Workflow도 충분히 이용해 볼 만한 것 같습니다.
읽어주셔서 감사합니다.