Hortonworks Sandbox를 AWS에서 사용하기
들어가며
최근에 ‘하둡과 스파크를 활용한 실용 데이터 과학’이라는 책을 읽고 따라해 보고 있다. 이 책에서는 실습을 위해 호튼웍스(Hortonworks)의 Sandbox 이미지를 사용해 보기를 권장하고 있다. 그런데 설치 방법을 찾다 보니, 권장 사양이 높은 것 같다는 생각이 들었다. 이 이미지를 VirtualBox에서 사용할 때, 메모리 용량이 8GB로 설정되어 있었다. 그런데 지금 내가 쓰고 있는 노트북의 메모리 용량이 8GB라 좀 어려울 것 같았다. 그래서 AWS에 이 이미지를 올려보게 되었다.
(주의: 이 글에서 설명하는 내용은 AWS의 Free Tier 범위를 넘어가므로 사용한 만큼 요금이 부과됩니다. 크레딧이 있거나 비용 지불이 가능한 경우에 사용하시기 바랍니다. 비용 발생에 대한 책임은 독자에게 있습니다.)
Hortonworks Sandbox 이미지 받기
위의 사이트에 들어가 보면, 설치 타입을 VMWare, Virtualbox, Docker 중 하나로 선택할 수 있다. 나는 Virtualbox를 선택했다. (참고로 Hortonworks는 최근에 클라우데라와 합병했다고 한다)
다운로드 받기 전에 이것저것 물어보는데, 아래의 체크박스에 체크하지 않아도 모든 텍스트박스만 채우면 받을 수 있다.
나는 2.5 버전을 받았다. 3.0, 2.6.5 버전은 AMI로 변환하는 과정에서 커널 문제 때문에 변환이 안 되어 이전 버전을 사용했다.
참고로 이미지 용량이 10GB를 넘으므로, 여유있게 기다리자. (집에서 다운로드 받는데 1시간 정도 걸렸다)
시작 전 세팅
먼저 IAM 계정을 설정하고, 내 노트북에는 AWS CLI를 설치했다.
IAM 계정 설정에 대해서는 AWS의 문서를 참고하면 된다. 굳이 내가 설명하지 않아도 될 것 같아 문서만 링크했다.
(물론 실제 운영 중인 서비스라면 AdministratorAccess를 부여하는 것은 지양해야 한다만, 설명의 편의를 위해 이렇게 진행하겠다)
그리고 AWS CLI 설치는 AWS 명령줄 인터페이스 문서를 참고한다.
파이썬이 설치되어 있다면, 터미널에서 python -m pip install awscli를 입력해서 설치하는 것이 가장 빠를 것이다.
S3 버킷에 가상 머신 이미지 업로드
여기부터 이미지를 import 하는 과정까지는 CLI로 진행해 보겠다.
먼저 버킷을 생성한다. <Bucket name>이라고 표시된 부분은 원하는 대로 변경한다.
aws s3api create-bucket --bucket <Bucket name> --create-bucket-configuration LocationConstraint=ap-northeast-2
{
"Location": "http://<Bucket name>.s3.amazonaws.com/"
}
참고로 us-east-1 리전 외에는 LocationConstraint 옵션을 주어야 한다. 나는 서울 리전(ap-northeast-2)에 버킷을 만들었다. (참고자료)
이제 다운로드 받은 이미지를 S3 버킷에 업로드한다. <Bucket name>은 앞에서 만든 버킷 이름으로 변경한다. 그리고 <file path and name>은 다운로드한 VM 이미지 파일의 전체 경로로 변경한다.
aws s3 cp <file path and name> s3://<Bucket name>/
참고로 aws s3api put-object를 이용하면 단일 작업으로 올릴 수 있는 파일 크기가 5GB로 제한되어 있으므로 업로드를 할 수 없다. 아마 이런 오류를 볼 수 있을 것이다.
An error occurred (EntityTooLarge) when calling the PutObject operation: Your proposed upload exceeds the maximum allowed size
위의 aws s3 cp를 이용하거나 멀티파트 업로드를 이용해 업로드하면 된다.
(이 작업도 시간이 많이 소요된다. 내 노트북으로는 30분 정도 걸렸던 것 같다.)
가상 머신 이미지를 AMI로 등록하기
가상 머신 이미지를 AMI로 등록하기 위해서는 vmimport라는 서비스 역할이 필요하며, IAM 정책을 역할에 연결해야 한다.
AWS 문서를 참조하여 IAM 역할을 만든 뒤 다음 단계로 진행한다.
이제 다음과 같이 JSON 파일을 만든 뒤 저장한다. (VirtualBox 이미지이므로, Format 속성을 ova로 설정한다.)
[
{
"Description": "<임의의 설명>",
"Format": "ova",
"UserBucket": {
"S3Bucket": "<bucket name>",
"S3Key": "<image name>"
}
}
]
이 파일을 저장한 뒤 다음 명령을 터미널에서 실행한다.
aws ec2 import-image --description "<임의의 설명>" --disk-containers "file://<작성한 JSON 파일의 위치>"
{
"Description": "<임의의 설명>",
"ImportTaskId": "import-ami-<자동으로 지정되는 숫자/알파벳>",
"Progress": "2",
"SnapshotDetails": [
{
"DiskImageSize": 0.0,
"Format": "OVA",
"UserBucket": {
"S3Bucket": "<bucket name>",
"S3Key": "<image file name>"
}
}
],
"Status": "active",
"StatusMessage": "pending"
}
이 작업도 시간이 오래 소요될 것이다. 작업 진행 중인 상태를 보려면 다음 명령을 입력한다.
aws ec2 describe-import-image-tasks --import-task-ids import-ami-<자동으로 지정되는 숫자/알파벳>
{
"ImportImageTasks": [
{
"Description": "<임의의 설명>",
"ImportTaskId": "import-ami-<자동으로 지정되는 숫자/알파벳>",
"Progress": "30",
"SnapshotDetails": [
{
"DiskImageSize": 11772940288.0,
"Format": "VMDK",
"Status": "completed",
"UserBucket": {
"S3Bucket": "<bucket name>",
"S3Key": "<image file name>"
}
}
],
"Status": "active",
"StatusMessage": "completed"
}
]
}
StatusMessage 값이 “completed"가 될 때까지 기다리면 이 AMI를 EC2에 올릴 수 있다.
{
"ImportImageTasks": [
{
"Architecture": "x86_64",
"Description": "<임의의 설명>",
"ImageId": "ami-<자동으로 지정되는 숫자/알파벳>",
"ImportTaskId": "import-ami-<자동으로 지정되는 숫자/알파벳>",
"LicenseType": "BYOL",
"Platform": "Linux",
"SnapshotDetails": [
{
"DeviceName": "/dev/sda1",
"DiskImageSize": 11772940288.0,
"Format": "VMDK",
"SnapshotId": "snap-04525706b9b899bf0",
"Status": "completed",
"UserBucket": {
"S3Bucket": "<bucket name>",
"S3Key": "<image file name>"
}
}
],
"Status": "completed"
}
]
}
EC2 설정하기
EC2 콘솔에서 인스턴스 시작을 클릭한다. 이 화면에서 왼쪽 메뉴에 있는 나의 AMI를 클릭한 뒤, 새로 생성된 AMI를 선택한다.
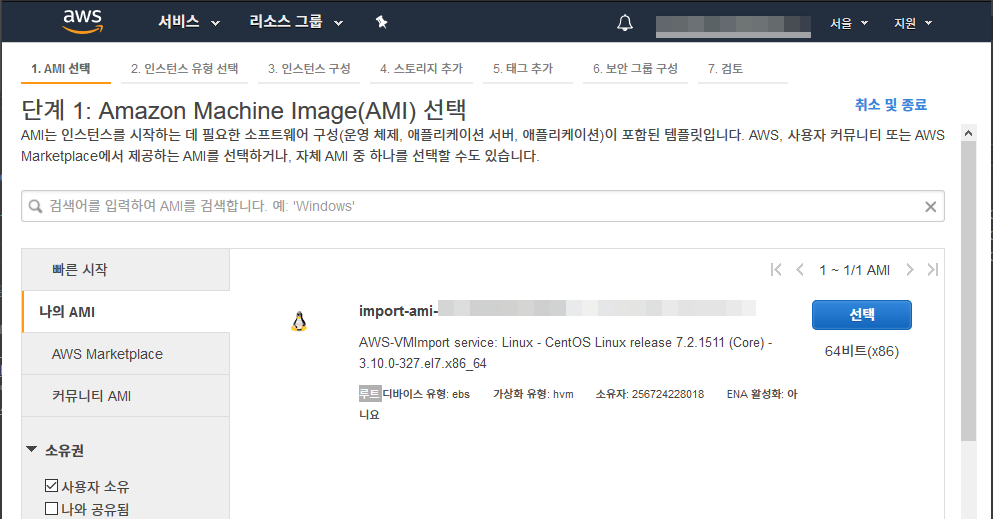
그 다음부터는 일반적인 EC2 인스턴스를 만드는 것과 같이 동일하게 진행하면 된다.
참고로 일부 인스턴스 유형은 제한되어 있으니 적절하게 선택하자.